Scaling Parallel Stockfish Analysis
Result: the Stockfish analysis pipeline went from 4.00 positions/sec on
one web server to a reliable 47-60 positions/sec on cloud CPU workers. The
rollout completed 251,166 position evaluations under a Stockfish 18, depth
18, MultiPV 3 contract.
The current production setting is batch size 32, max_containers=100, a
300s per-position cap, and buffered write-back. Earlier direct-writeback runs
modeled around $0.0000200 per position; the current cpu=0.25 buffered path
models closer to $0.0000053.
The interesting part was not proving that Stockfish can run in parallel. A chess position is already an independent unit of engine work. The hard part was finding the operating point that kept cost bounded, failures recoverable, and depth semantics accurate.
The implementation here used Railway for the control plane and Modal for Stockfish workers, but the reusable parts are the workload model, measurement method, and failure constraints.
Transferable lesson: don’t start by maximizing worker count. Start by defining the engine contract, the retry unit, the write-back contract, and the measurement ledger. Then raise concurrency.
This applies best to high-volume offline analysis: many independent positions, strict quality requirements, and enough work that retries matter as much as raw speed. It is less relevant to single-game interactive analysis, where latency dominates.
Measured production setting:
| Setting | Value |
|---|---|
| Engine | Stockfish 18 |
| Depth | 18 |
| MultiPV | 3 |
| Worker CPU | 0.25 |
| Batch size | 32 |
| Max containers | 100 |
| Per-position cap | 300s |
| Write-back mode | buffered |
| Broad-run throughput | 47-60 pos/s |
| Modeled cost | about $0.0000053 per completed position |
Decision record:
| Decision | Current value |
|---|---|
| Work unit | position_key, not game id |
| Quality contract | requested Stockfish 18, depth 18, MultiPV 3 |
| Current setting | batch 32, 100 containers, 300s cap, buffered write-back |
| Why this point | bounded cost, retryable tails, reliable cleanup, reached depth recorded on every result |
| Revisit when | provider cap changes, cache hit rate rises, write-back drain dominates, or tail positions dominate wall time |
Workload Definition
The user-facing object is a chess game. The compute object is a position.
The system ingests games, extracts positions, deduplicates them by position_key, evaluates missing positions, then materializes per-move eval rows once the before/after positions are available.
PGN games
-> positions
-> unique position keys
-> Stockfish queue
-> position eval cache
-> move-level eval rows
-> reports, drills, prep, review
The production contract was Stockfish 18, requested depth 18, MultiPV 3,
queued by position_key, with SQLite as the source of truth and cloud CPU
containers as the worker pool.
The eval contract is part of the data model. A depth 18 MultiPV 3 row
is not interchangeable with a public cache row from a different engine, depth,
or MultiPV shape. The system stores provenance so future code can distinguish
computed rows, cache hits, and deeper references.
Methodology
Most tables use compact run labels. 25g, 100g, and 500g mean work
prepared from that many games. b32 means batch size 32. c50 means worker
cap 50. t300 means a 300s per-position cap.
The measurements use three labels: observed for worker or ledger rows, estimated for pre-submit cost estimates, and modeled for later operating models after changing CPU fraction or write-back shape.
Throughput numbers use submit wall time or server batch span, depending on what the run recorded. They are good enough to compare operating points, not to claim a universal Stockfish benchmark.
The source workload was my own historical chess archive. The production database recorded jobs, batches, queue states, materialized eval counts, worker wall time, write-back time, and cost estimates. Profile-only depth experiments ran through the same worker path but did not write results into production eval tables.
One count caveat: the baseline status line and the final workload count are not
the same unit. The baseline line was a phase counter from the old per-user
backfill path. The final 251,166 number includes position-key dedupe,
before/after position evals, recompute work, retries, and move-eval reuse.
Treat it as the final analyzed workload size, not as the number of games or
moves.
I am not publishing the raw experiment table as a downloadable artifact. The post includes the measured rows needed for the argument; the full operator ledger stays in the project notes.
Baseline
Baseline: 4.00 positions/sec, with a 9.1h ETA still visible mid-run.
The original path ran Stockfish inside the Railway web runtime. It was simple and correct enough for small imports, but the wrong shape for a large archive.
The live status line looked like this:
stockfish phase: 6350/137250 (cache=6043, errors=0) 4.00/s ETA 9.1h
That line was accurate. It also showed the ceiling. A larger web box would improve throughput linearly, but the work would still be tied to one long-running process, one deployment lifecycle, and one machine.
The batch workload needed parallelism bounded by worker capacity, failure scoped to a batch or position, cost caps per job, and durable queue state. The first scaling target was measured throughput with enough state to recover.
Control Plane
More workers need a ledger. The ledger was the main infrastructure.
The control plane used five main tables:
analysis_jobs: parent request, submitter, purpose, engine contract, cost cap, aggregate status.analysis_job_batches: worker shard status, accepted count, materialized count, worker wall time, write-back timing.analysis_queue: position-key status and normalized eval result.analysis_requests: who asked for which position and why.evals: move-level materialized rows for reports and training surfaces.
Workers did not discover work. The control plane claimed position keys, created job and batch rows, then sent those claimed keys to the worker pool. The database stayed the source of truth for ownership, status, caps, retries, and materialization.
Parent job counters eventually derived from canonical batch rows because write-back is effectively at-least-once: a client retry can submit the same completed batch payload again.
SELECT
SUM(accepted) AS accepted,
SUM(materialized) AS materialized,
SUM(CASE WHEN status != 'completed' THEN 1 ELSE 0 END) AS open_batches
FROM analysis_job_batches
WHERE job_id = ?
If duplicate callbacks require manual audit, the throughput number is not trustworthy.
Throughput Results
The stable jump was roughly 12-15x over the single-server baseline.
The reliable throughput gains came from changing several variables together: batch size, container cap, per-position time cap, database query shape, and callback idempotency.
Read this as a tuning ladder, not a pure worker-count benchmark.
| Run Shape | Accepted | Batches | Wall/Span | Throughput | Est. Cost |
|---|---|---|---|---|---|
25g b32 c25 |
3,006 |
94 |
206.344s |
14.57 pos/s |
$0.06012 |
100g b32 c50 |
12,701 |
397 |
365.205s |
34.78 pos/s |
$0.25402 |
100g b32 c100 t300 |
10,282 |
322 |
216.439s |
47.50 pos/s |
$0.20564 |
500g b32 c100 t300 |
45,429 |
1,420 |
752.324s |
60.39 pos/s |
$0.90858 |
The final broad chunks stayed in the same band:
| Job | Accepted | Span | Throughput |
|---|---|---|---|
30 |
45,429 |
752.324s |
60.39 pos/s |
31 |
38,248 |
~663.0s |
57.69 pos/s |
32 |
32,857 |
~599.0s |
54.85 pos/s |
33 |
27,650 |
~562.0s |
49.20 pos/s |
34 |
22,371 |
~444.0s |
50.39 pos/s |
35 |
15,951 |
~326.0s |
48.93 pos/s |
36 |
3,403 |
~72.0s |
47.26 pos/s |
The production setting was the highest-concurrency setup that kept failures diagnosable and cleanup reliable. The internal run ledger also records batch counts, materialized evals, write-back timings, and cost estimates.
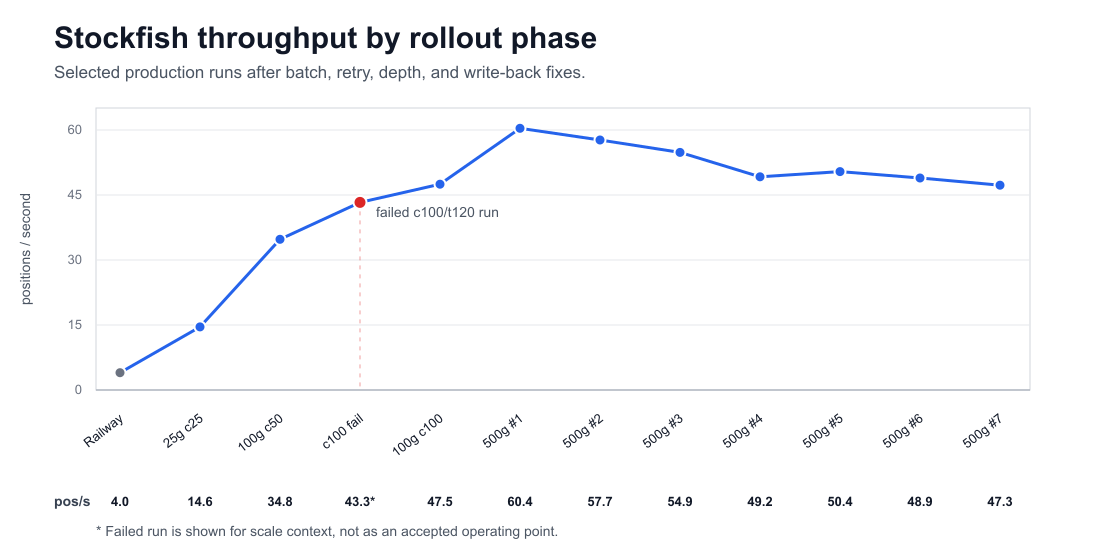 Throughput improved only after the surrounding queue, write-back, and retry paths could tolerate production-scale failures.
Throughput improved only after the surrounding queue, write-back, and retry paths could tolerate production-scale failures.
Batch Size
Batch size is retry granularity. Larger batches reduce scheduling and callback overhead, but make each tail failure more expensive to isolate.
The rollout saw this directly. A 25g b64 c25 run completed 44/45 batches and accepted 2,767 positions before one batch failed a depth guard. Later tail investigations narrowed failures from 32 positions to 8, then to one position.
The final batch size of 32 was a compromise. Batch size 1 is best for
diagnostics but too expensive for broad orchestration. Batch sizes 8-16 are
good retry shapes. Batch size 64+ reduces batch count but makes tail
isolation worse. The retry tool could split failed work down to single
positions, which mattered more than squeezing out a little scheduling overhead.
Rule of thumb: choose the largest batch size you can comfortably retry.
Worker Count
Worker count helped after the control plane could absorb the callback rate.
The jump from 25 to 50 containers was large: one clean 50-container
validation reached 34.78 positions/sec. A 100-container run with a 300s
cap reached 47.50 positions/sec on a 100-game chunk, and the first 500-game
chunk reached 60.39 positions/sec.
The measured operating point is currently bounded by provider workspace capacity and the single write-back target. Direct worker-to-web callbacks are a poor long-term write path when hundreds of workers finish near the same time. Buffered shards move the burst into Modal Volume, then the server drains results in a controlled phase.
That means max_containers was not the only ceiling. Past a certain point, the
next bottleneck becomes scheduling, shard handling, drain rate, or database
materialization.
The cpu=0.25 setting worked because the workload had many independent
positions and correctness was enforced by reached-depth validation. Cheaper
workers with enough parallelism were a better default than fewer larger
workers, until tail positions or provider limits became the bottleneck.
Cost
The cost win came from worker shape and write-back shape, not from lower
analysis standards. Direct-writeback runs landed around $0.0000200 per
submitted position. The newer scheduled runner uses cpu=0.25 cost scaling and
buffered write-back, about a quarter of the older estimate.
| Phase | Example | Positions | Estimated Cost | Cost / Position |
|---|---|---|---|---|
| broad direct-writeback rollout | job 30 |
45,429 |
$0.90858 |
$0.0000200 |
buffered cpu=0.25 path |
job 63 |
235 |
$0.001175 |
$0.0000050 |
The Modal dashboard for the experimentation window showed $17.43 total
resource spend: $16.69 CPU and $0.74 memory. That includes failed probes,
profiling, retries, depth experiments, and production rollout work. It is the
right number for “what did this exploration cost,” not the marginal cost of the
final operating point.
The discipline was enforcing a cost cap before worker submission and writing the estimate into the job ledger.
Keep three numbers separate: estimated cost before submission, observed provider bill after the run, and cost per accepted position after retries and cache reuse. They answer different questions.
Correctness Constraints
The engine contract needed more than depth=18.
Depth is not a wall-clock budget. A depth-only Stockfish call can run until an outer platform timeout kills it. The production worker needed both a requested depth and a per-position time cap.
The worker also needed a correct engine lifecycle boundary. Reusing one
Stockfish process across unrelated FENs without a changing game= token made
python-chess treat the whole shard as one implicit game. It did not send
ucinewgame between unrelated positions. One worker shard hit the platform
timeout at 1800s; local replay of all 64 positions completed in about
91.8s. With a changing game= token and ucinewgame, the problematic
position reached [18,18,18] in under a second.
The boundary fix was small:
info = engine.analyse(
board,
chess.engine.Limit(depth=18, time=300),
multipv=3,
game=position_key,
)
The important part is not the exact wrapper. It is that unrelated positions need unrelated engine-game identity.
Pathological Positions
The rollout recorded the actual positions, not just aggregate failures. The important cases fell into two buckets.
First, some positions were too strict for the contract we actually consume. Boards in this section are oriented from the side to move.

18; alternate line stopped at 17.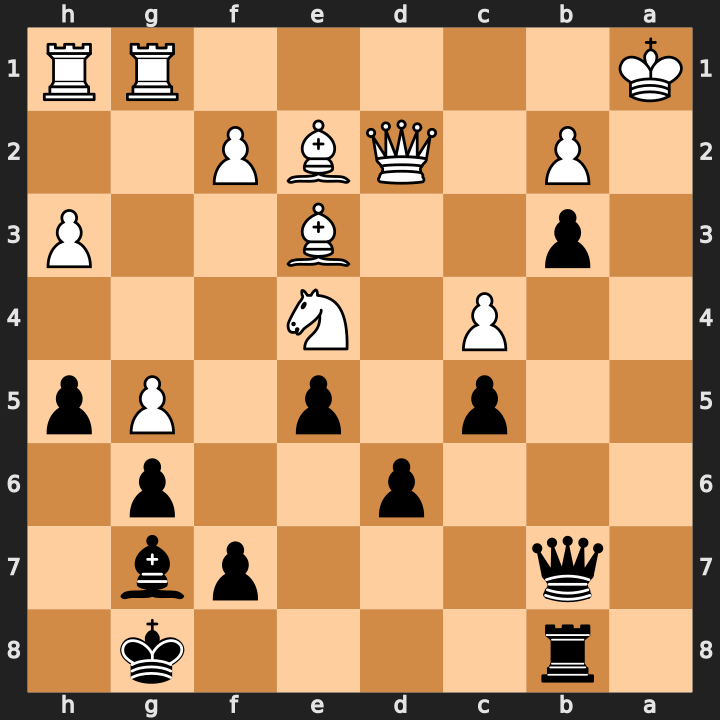
[15,15,14]; accepted as low-depth fallback.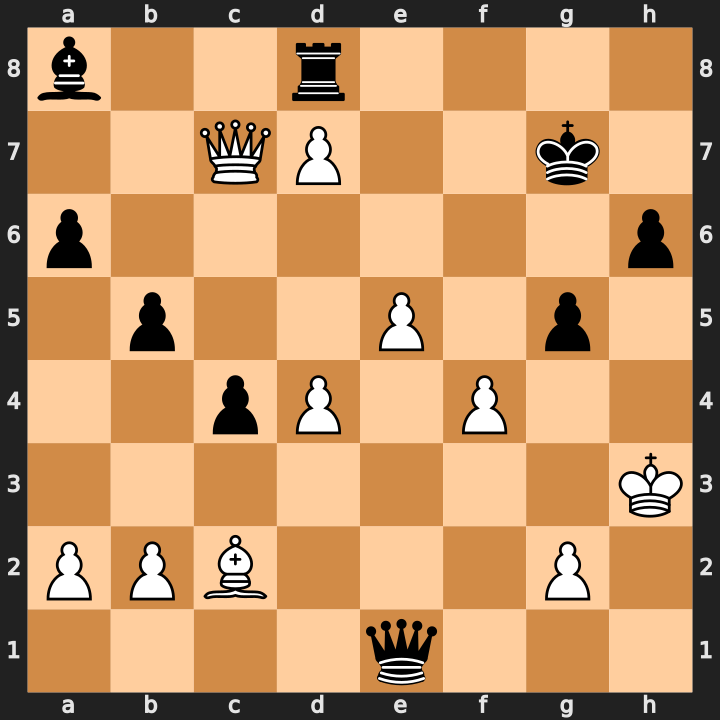
[17,17,17]; stored result_depth=17.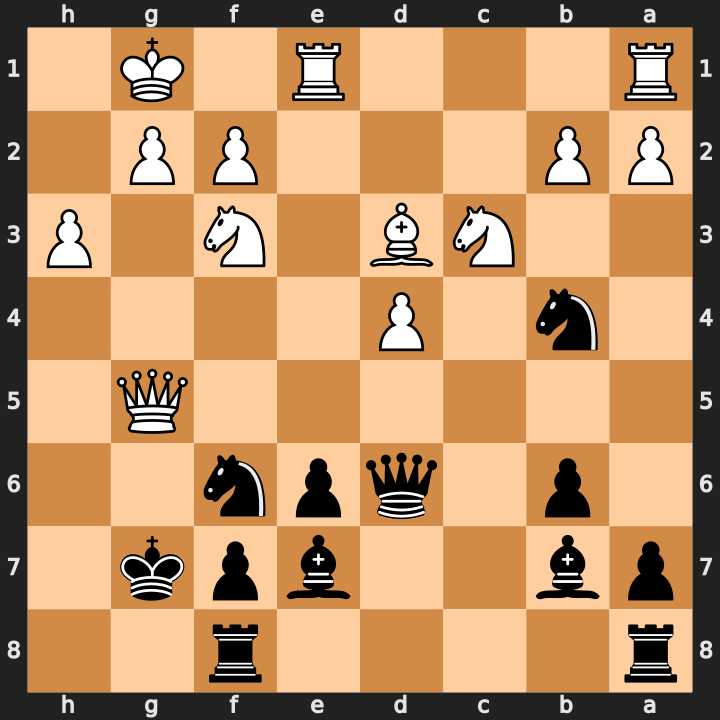
[17]; stored result_multipv=0/3.- MultiPV tail.
Retrying the failed batch
32 -> 8 -> 1isolated this six-piece queen-and-pawn endgame. Stockfish returned depths[18, 18, 17]: the best line reached depth18, while the third PV remained one ply shallow. The accepted row records best movef3d5, eval-8115cp,requested_multipv=3, andresult_multipv=2.
FEN:8/5p2/3Kp1p1/8/8/5q2/5k2/8 b - -. - Magnus true pathological tail.
Strict retries at
120sand180sstill returned only depths[15, 15, 14]. The final non-strict fallback storedresult_depth=15, best moveb7a7, eval-933cp, and explicit low-depth provenance.
FEN:1r4k1/1q3pb1/3p2p1/2p1p1Pp/2P1N3/1p2B2P/1P1QBP2/K5RR b - -. - Low-depth fallback 1.
The strict run stopped after
60.013swith depths[17, 17, 17]. The fallback row recordsresult_depth=17,result_multipv=2/3, best moveh3g4, eval-847cp, and90,863,715nodes.
FEN:b2r4/2QP2k1/p6p/1p2P1p1/2pP1P2/7K/PPB3P1/4q3 w - -. - Low-depth fallback 2.
The strict run stopped after
60.010swith depths[17]. The fallback row recordsresult_depth=17,result_multipv=0/3, best moveg7h8, eval+761cp, and89,579,084nodes.
FEN:r4r2/pb2bpk1/1p1qpn2/6Q1/1n1P4/2NB1N1P/PP3PP1/R3R1K1 b - -.
Second, at least one position was not bad, just slow under the first cap:
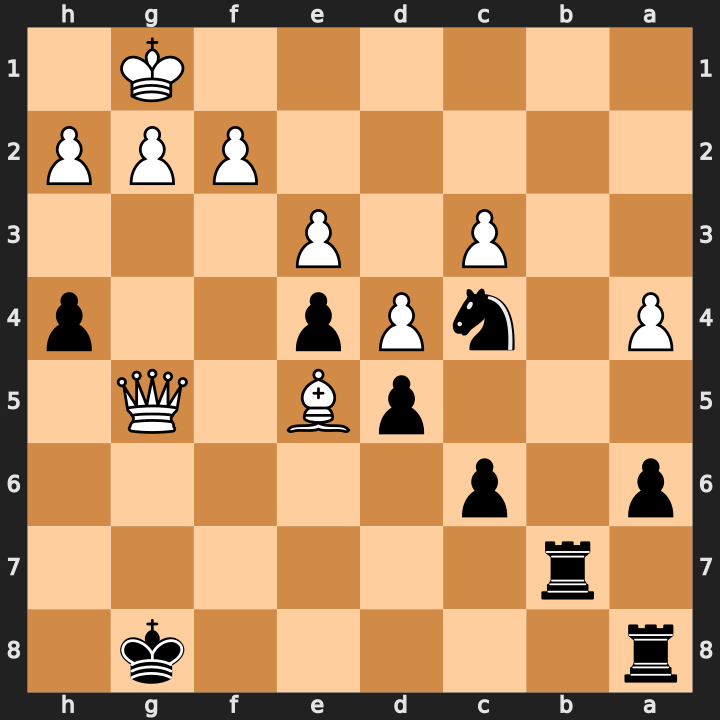
[18,18,18] at 300s.- True
120stail. At120s, one single-position retry returned best-line depths[17, 17, 18], while31/32neighboring retries completed quickly. With a300scap, the exact same position reached[18, 18, 18]in140.171s.
FEN:r5k1/1r6/p1p5/3pB1Q1/P1nPp2p/2P1P3/5PPP/6K1 b - -.
Those examples explain why the system stores actual result depth and actual
MultiPV count instead of pretending every accepted row satisfied depth 18 and
MultiPV 3.
The rollout also recorded several failure shapes:
| Case | Signal | Resolution |
|---|---|---|
| engine lifecycle | one shard hit the 1800s platform timeout; local replay of 64 positions took 91.8s |
give unrelated FENs distinct game= identity so ucinewgame fires |
| MultiPV depth guard | 32 -> 8 -> 1 retry split isolated a legal position with shallow alternate PV lines |
validate the consumed best line and store result_multipv |
| true slow tail | 31/32 single-position retries finished quickly; one missed 120s but completed at 300s in 140.171s |
keep a higher per-position cap for the broad contract |
| low-depth fallback | isolated legal positions still could not satisfy all depth/MultiPV targets under the fallback cap | accept only with explicit result_depth and result_multipv provenance |
| depth-cost tail | depth 36/MultiPV 1 was 41.44x slower than depth 18/MultiPV 3 on the sample |
don’t make deep recompute the default path for every cache miss |
Correctness Rules
The final correctness rules:
- send a new-game boundary per unrelated position;
- use a per-position time cap;
- validate that consumed best lines reached requested depth;
- store
requested_multipvandresult_multipv; - derive parent counters from batch rows;
- treat completed batch rows as final.
Main non-obvious lesson: engine protocol semantics become production correctness when the engine runs in a batch worker.
If a benchmark only measures final throughput and ignores reached depth, it can look successful while silently degrading analysis quality.
Depth And Quality Tradeoff
Higher depth is a cost multiplier, not a free quality knob.
A profile-only sample of 10 positions compared several contracts:
| Engine Contract | Worker Wall | Slowest Position | Relative To Depth 18 / MultiPV 3 |
|---|---|---|---|
depth 18, MultiPV 1 |
5.301s |
0.571s |
0.51x |
depth 18, MultiPV 3 |
10.329s |
2.442s |
1.00x |
depth 24, MultiPV 1 |
24.861s |
5.728s |
2.41x |
depth 24, MultiPV 3 |
56.252s |
13.428s |
5.45x |
depth 30, MultiPV 1 |
87.375s |
16.263s |
8.46x |
depth 36, MultiPV 1 |
428.071s |
106.782s |
41.44x |
This made the production choice clear: keep cache misses at
Stockfish 18, depth 18, MultiPV 3; use deeper public cache hits when
provenance matches the product need; do not make depth 30+ or 36 the
default recompute target for every personal-game tail position.
Depth 18 is not universally “enough.” It is the default compute contract chosen
for this workload after pricing the curve.
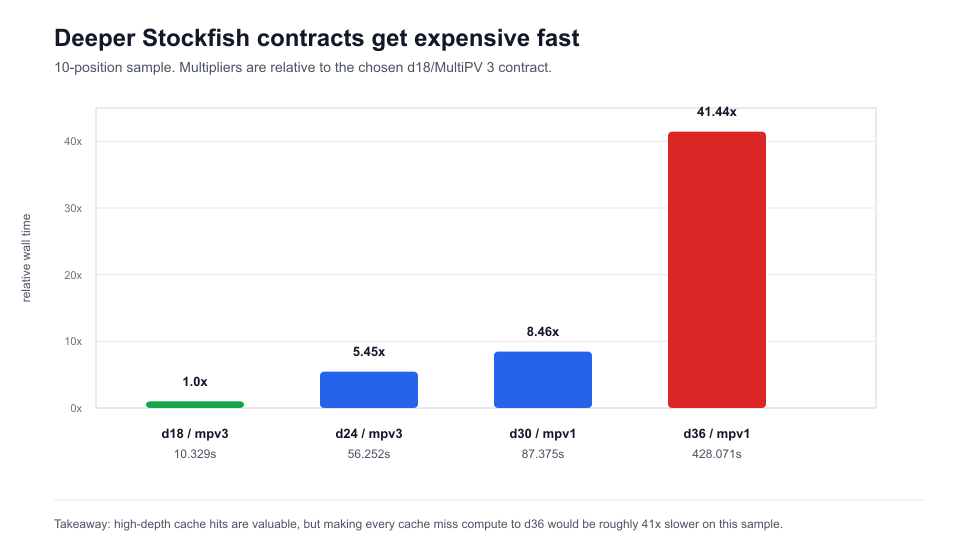 Deeper analysis may be useful, but it changes the cost shape by multiples, not percentages.
Deeper analysis may be useful, but it changes the cost shape by multiples, not percentages.
Cache Behavior
Local position-key reuse was valuable. Public cache probing was not ready to sit inline on large prepares.
During broad prepares, local cache read-through materialized thousands of move evals before cloud compute. That should stay enabled. It is deterministic, local, and keyed to the same position/eval contract.
Public Lichess/Stockpile-style cache probing had two problems in the initial
tests: the first 50 sampled positions had 0 hits, and later sanity checks
hit rate-limit behavior. That means public API probing cannot block broad
production prepare.
Current policy:
- use local/global position cache read-through;
- keep public cache probes bounded or off for large runs;
- add incremental, persistent, backoff-aware probing before trying again;
- store source, engine version, depth, MultiPV, fetched-at status, and dataset metadata;
- do not treat private depth-18 rows as interchangeable with deeper public rows.
Cache is useful when its contract fits. It is not a substitute for a bounded path for cache misses.
Product rule: cache hits are compute results with provenance. If source, engine, depth, MultiPV, or latency does not fit the product contract, treat the cache as optional acceleration.
Limits of This Benchmark
These numbers are useful operating data, not a universal Stockfish benchmark.
The workload is one personal chess archive. The engine contract is fixed at
Stockfish 18, depth 18, MultiPV 3. The implementation used Railway plus
SQLite as the control plane and Modal CPU containers under the account limits
available during this rollout. Different depths, MultiPV counts, hardware,
position distributions, cache hit rates, and provider limits will change the
result.
The transferable part is the measurement method: define the eval contract, record job and batch state, preserve provenance, cap spend before submission, and change one bottleneck at a time.
Bottlenecks Found
The bottlenecks moved as scale increased.
| Bottleneck | Symptom | Resolution |
|---|---|---|
| single web CPU | about 4 pos/s and multi-hour ETA |
fan out independent position keys |
| batch tail | one slow position held a shard | batch size 32, retry splits, per-position cap |
| engine lifecycle | platform timeout despite fast local replay | ucinewgame boundary per position |
| MultiPV depth guard | valid best line rejected | validate consumed line, store result MultiPV |
| SQLite key-set size | 500-game prepare hit SQL variable limit | chunk queries and use temp tables |
| duplicate callbacks | parent job overcounted | derive counters from canonical batch rows |
| late error callback | completed batch marked error | completed rows are final |
| public cache latency | prepare stalled or rate-limited | make public probes bounded and incremental |
| deploy feedback loop | image push took 163s |
move heavy ML stack out of web image |
| workspace cap | 100-container runs became the practical ceiling | accept cap or seek higher compute capacity |
The image-size fix was not part of Stockfish compute, but it mattered to
iteration speed. The web image went from 2.85 GB to 189.5 MB, and image
push dropped from 163s to 8.1s.
Recurring pattern: after one bottleneck moved, the next one was usually outside Stockfish.
Measured Operating Point
Expected behavior for the current production setting:
| Metric | Expected Range |
|---|---|
| Broad-run throughput | 47-60 pos/s |
| Queue cleanup after completion | no leftover pending, running, or error rows |
| Write-back p95 on larger chunks | sub-second in recorded runs |
| Cost per completed position | roughly $0.000005 at the cpu=0.25 model |
This is a stable operating point, not a permanent optimum. Change it when tail positions dominate wall time, drain wall time becomes material, provider bills diverge from the model, queue rows become stale, cache hit rate becomes high and reliable, or the batch provider raises the account limit.
The next 10x jump probably does not come from tuning max_containers inside
the same cap. It comes from one of three changes:
- The batch provider raises the workspace/container limit.
- The workload splits across independent compute capacity.
- More positions are satisfied by a provenance-compatible cache.
Until then, the 100-container buffered path is the production default.
What Should Transfer
The durable parts are not the exact provider, price, or batch size.
| Principle | Measured instance |
|---|---|
| Define the eval contract first | Stockfish 18, depth 18, MultiPV 3 |
| Queue immutable work units | position_key, not game id |
| Treat batch size as retry granularity | batch size 32 became the default |
| Separate requested and reached quality | requested depth vs reached depth, requested MultiPV vs result MultiPV |
| Make write-back idempotent | parent counters derived from batch rows |
| Keep cache provenance visible | source, engine, depth, MultiPV, fetched-at metadata |
| Cap spend before submission | cost cap recorded on each job |
If another system changes engine version, target depth, hardware, provider, or position distribution, the measured values should change. The principles should not.
Rerun This Benchmark
Rerun when any of these change:
- engine version or UCI options;
- requested depth or MultiPV count;
- per-position time cap;
- CPU shape, worker count, or provider limit;
- batch size;
- write-back path;
- cache source and hit rate;
- position distribution.
The fastest setting for a blitz archive may not be the fastest setting for an opening database, endgame study set, or engine-vs-engine corpus. The minimum useful benchmark loop:
- Sample positions from the real workload, not only starting positions or test FENs.
- Profile the target engine contract and at least one deeper contract.
- Run a small batch ladder:
1,8,16,32,64. - Run a worker-count ladder after retries and write-back are reliable.
- Measure worker wall time, submit span, write-back time, and leftover queue rows separately.
- Track estimated cost before submission and actual provider spend afterward.
- Validate reached depth and persisted provenance, not only throughput.
- Repeat the same sample after changing provider, depth, or worker shape.
Lessons
- Define the engine contract before scaling compute.
- Queue position keys, not games.
- Treat batch size as retry granularity.
- Add a wall-clock cap. Depth is not a budget.
- Treat engine lifecycle boundaries as correctness requirements.
- Make idempotency part of the performance work.
- Keep cache provenance visible.
- Optimize deploy feedback loops during production tuning.
Do not regress:
- Send a distinct engine-game identity for unrelated positions.
- Store requested and reached depth separately.
- Store requested and reached MultiPV separately.
- Queue and dedupe by
position_key. - Make batch write-back idempotent.
- Keep failed batches retryable at smaller granularity.
- Treat low-depth fallbacks as explicit provenance, not as satisfied depth
18. - End production runs with
pending=0,running=0,error=0.